How Does GenAI Powered Search Engine Work?

Generative Artificial Intelligence (GenAI) technology is setting a new trend in how information is being consumed in this AI-first era. It is built on top of Large Language Models (LLMs), which play a huge role in building an assistive search engine that is powered by GenAI capabilities.
The problem with LLMs is that they cannot provide any recent or present information as they need months to retrain with new data. To overcome this limitation, an innovative architecture is proposed that sits on top of LLMs.
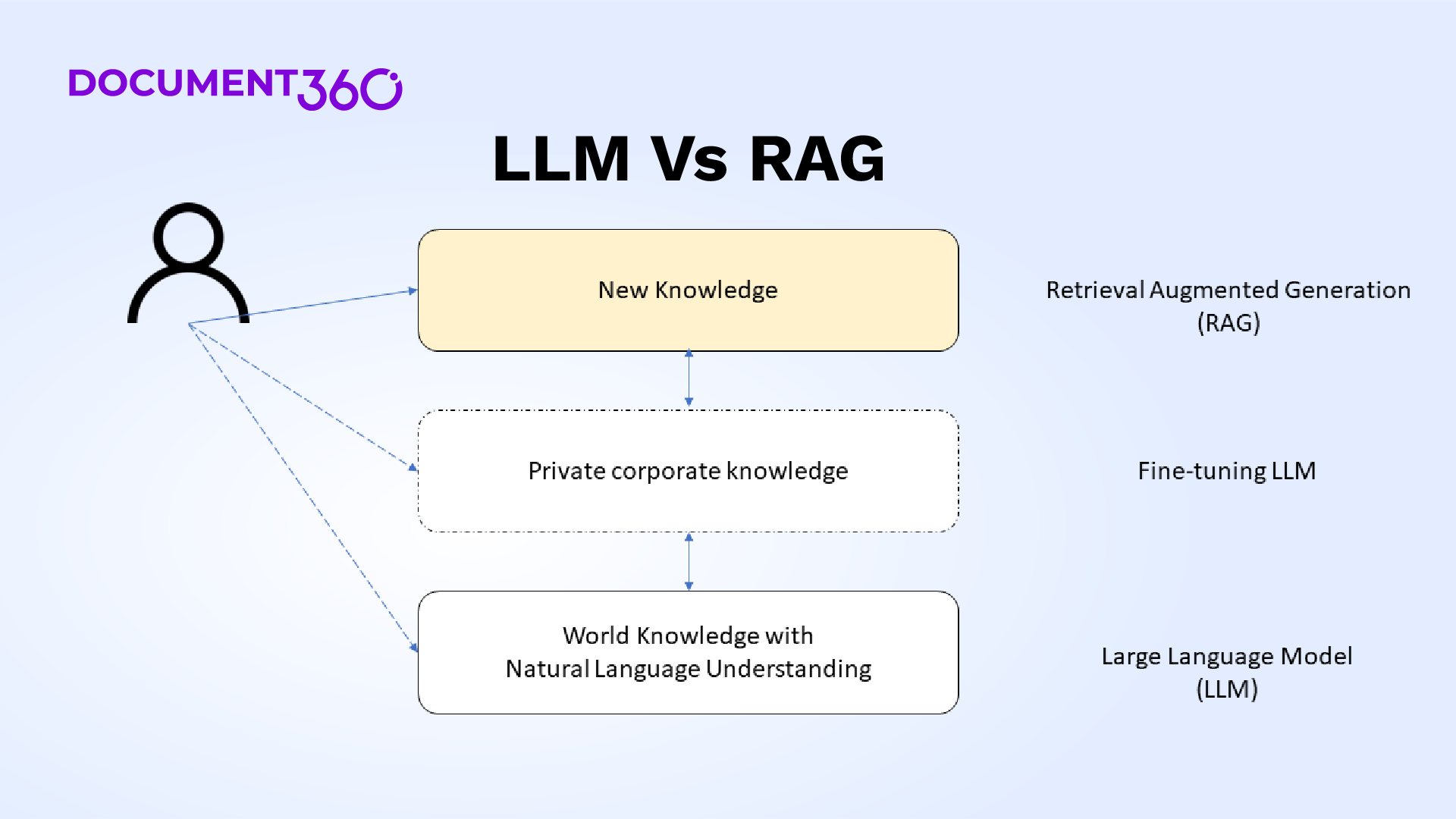
What is the Retrieval Augmented Generation (RAG) framework?
The Retrieval Augmented Generation (RAG) is an elegant way to augment recent or new information to be presented to the underlying LLMs such that it can understand the question that seeks new information. The RAG framework powers all the GenAI-based search engines or any search engine that provides context-aware answers to customers’ questions.
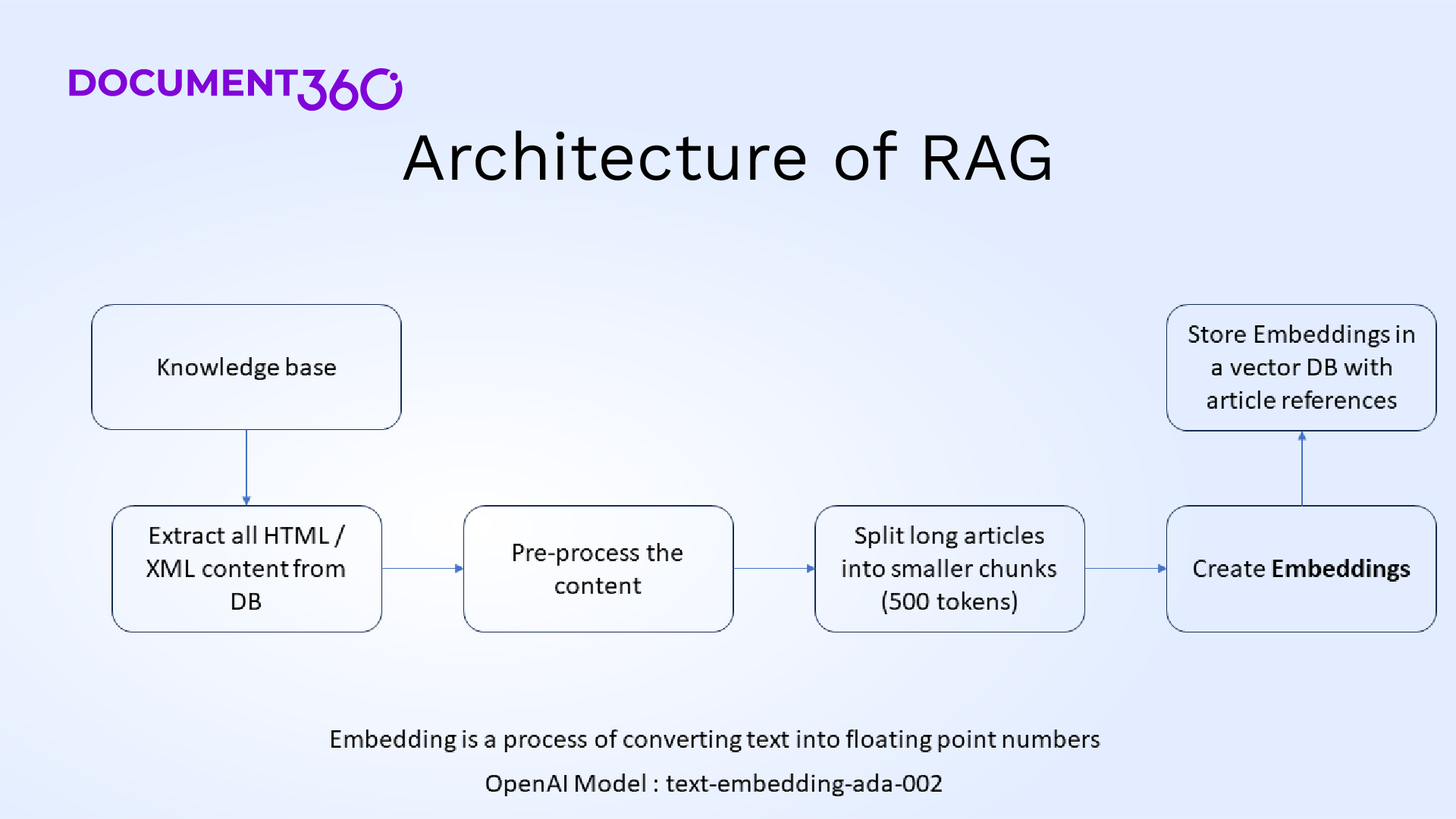
RAG architecture
The RAG architecture consists of a Retriever Module and a Generator Module. For RAG architecture to work, we need to chunk all the knowledge base content into small chunks. There are many ways to chunk all the knowledge base content, such as
Chunk them based on content hierarchy
Chunk them based on the use case
Chunk them based on content type and use case
Once the text data is chunked, then all these chunks need to be converted into text embedding. A plethora of APIs are available from GenAI tool vendors whereby the embedding model is a popular API quickly and cheaply. OpenAI Ada text embedding model is a popular API that is widely used.
The next step in the process is to store all text embeddings along with their related chunks and metadata in a vector database.
To continue reading about how GenAI powered search engine work? Click here



